FILIP NYGREN
AI & Gameplay Programmer
Specialization project:
Goal-Oriented Action Planning
Games can provide us with "fun" in a multitude of ways. But the most interesting one for me is using reasoning and logic to figure out and overcome the system. The game, in a sense, can be a puzzle, the inner workings and mechanics of which the designers have hidden from the player. This is why I am fascinated by game AI.
I first heard about GOAP during the AI programming course at The Game Assembly, and decided that it would be fun spend the five weeks we were given to have a go at implementing it! The system has been used in multiple games, most notably the 2005 game F.E.A.R. by Monolith Productions. Some of the material I used when researching GOAP was written by Jeff Orkin at Monolith, who implemented the system when developing F.E.A.R.
Table of Contents
Background
What is Goal-Oriented Action Planning?
Goal-Oriented Action Planning is a decision making system for AI actors in games. Each type of AI actor is given one or more goals to achieve, as well as a set of actions it can take to reach those goals. The AI actor will also be equipped with a planner module, which will select a goal to achieve and decide which sequence of actions will achieve that goal.
Actions can also has a cost associated with them. The costs of actions can enable the AI designer to make the AI actor prefer certain actions over others, if they can perform them given the circumstance. If the plan is completed, aborted, or can't be performed because the situation has changed, the planner will make a new plan.
The Technical Details
So how does all this actually work in practice? Most of the mechanisms behind the system uses so called world states. A world state is a pair of values, the first value being a text string, the second is some value that can be changed (in this project only true/false, i.e. a bool).
The goals of the AI actor are expressed in terms of these world states. For example, a goal could be to (attempt to) kill the player. So the world state "isAttacking" starts out being "false", and the AI actor will attempt to change their world state "isAttacking" to "true". A goal can therefore also be called a "desired world state".
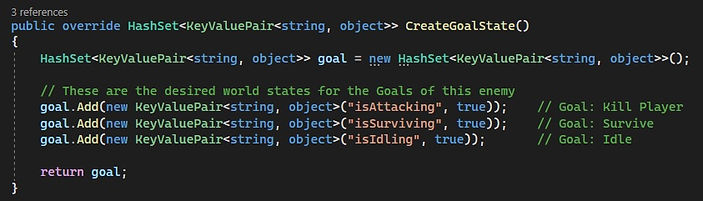
Each enemy type can have their own set of goals to achieve, the first being the top priority goal.
The next thing that happens, after choosing the first goal, when the AI actor makes a plan, is attempting to find an action that has the effect of setting "isAttacking" to "true". The effects of an action are the changes of the world state that performing the action will do.
Actions may also have preconditions associated with them. Preconditions are world states that must be satisfied in order for an action to be possible to perform (or planned for).

Preconditions, effects, and cost of the RangedAttack action.
If the preconditions for the action are not met, the planner will look for actions that satisfy those preconditions. For example, we need to be near the target in order to perform a ranged attack, so the planner will look for an action that will set "nearTarget" to "true".
The planner will keep doing this all the way back to the current situation, constructing in this way a "path" or sequence of actions. It will, in fact, construct every such path of actions, and choosing the one with the lowest total cost. The system allows the designer to assign a cost to each action, which makes it possible to design the AI actor to prefer certain actions, if it multiple actions are valid. This "pathfinding" process on actions utilizes the A* algorithm.
The RangedAttack action above also has two more preconditions, as you can see. This is because I designed the AI actor to adopt a more defensive attack strategy if "recentlyHit" by the player, and because I want it to perform a different attack when hiding in cover.
The system with actions, effects, preconditions and costs makes for a flexible decision making system: you can simply add more actions to expand the behaviour of the AI actor, and the AI actor will take care of the rest. This is really the strength of GOAP, because there is no need to consider each individual "state" transition. It also means it will be harder to outsmart the AI actor. They will be behaving more unpredictably, because the best plan may not always be to run right at the player, or even attacking as the first action, but instead take the long way around to flank, or retreat and prepare an ambush.
Goal
-
Implement a system of Goal-Oriented Action Planning in Unity.
-
Design two enemy types utilizing the system, displaying at least three planning branches.
-
Create a scene in Unity for showcasing the results.
During the research phase of the project, I saw several examples of GOAP being used to control AI in non-combat situations, moving around and gathering resources and similar. This seemed to be an easier goal to reach, but I really wanted to do a combat-oriented GOAP system, one that would respond to player actions.
For the GOAP to really shine, the enemy AI would need to have, in my opinion, at least three different "types" of behaviour, and not just "attack" and "defend", in order for the observer to percieve that the enemy actually does any type of planning, and that it is reacting to the situation.
I decided to work in Unity, because we have not had the chance to work in Unreal at the school. Compared to the various in-house engines we've worked in, Unity will have, by far, the most stable and working tools and features, that will allow me to focus on the gameplay aspects of the project, and not be held by back technical difficulties.
Development Process
Week 1: Research & Framework
The first week was my pre-production phase, mostly researching GOAP by reading papers and using online resources. My main resource was the webpage for Jeff Orkin of Monolith Productions, most notably the paper "3 States and a Plan: The AI of F.E.A.R."
I decided to use a similar structure of GOAP as the one Orkin used for F.E.A.R., where the GOAP system is complemented by a state machine of three states: Idle, Move, and PerformAction.
The main effect of using this structure, is that you can tag certain actions requiring to be "in range" of their target to be able to perform the action. For an action requiring to be in range, the "MoveTo" state will be pushed to be the active one, until the AI actor is in range of the target, and then the "PerformAction" state is pushed. This way, there is no need for actions to handle movement.
By the end of the first week, I was well on my way with the basic framework of the system, but the AI actor was still doing nothing. Luckily, by the last few hours of the week, I found the reason for this! It was pushing the "PerformAction" state instead of the "MoveTo" state, and thus I had an enemy correctly forming a plan and taking an action. Success!

The AI actor performing to "GotoTarget" action.
Week 2: Proof of Concept
Now it was time to add some more actions, and actually have the AI actor perform a complete loop of planning, taking actions, and replanning. The first problem I ran into was this: the final action of the plan, for example "RangedAttack" needed to have the effect of "isAttacking = true", or else the planner would never consider that action, since it did not lead to completing the goal of attacking the player.
But if the RangedAttack action had the effect of setting "isAttacking = true", then next time it made a plan, the goal was already fulfilled, so no new plan was made, making the AI actor just stand there and do nothing. I solved this by setting all goals to be "unfulfilled" after a plan was carried out.

The forming and carrying out of a plan.
Week 3: More Actions, More Goals
The AI actor can now plan for and execute one type of behaviour, but the whole point of GOAP is that the AI actor can make new plans on the fly, as circumstances change. First of all, I implemented a melee attack action. The AI actor will always prefer to do this over a Ranged attack, but it will only consider the melee action if the player is very close.
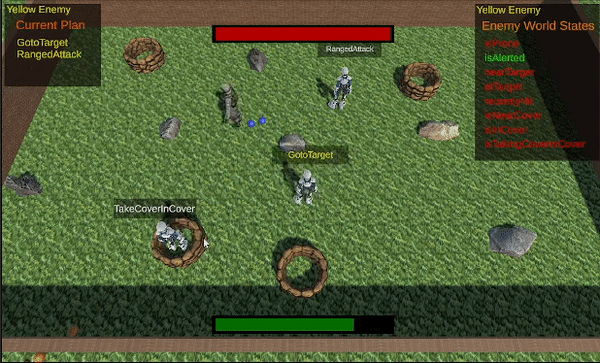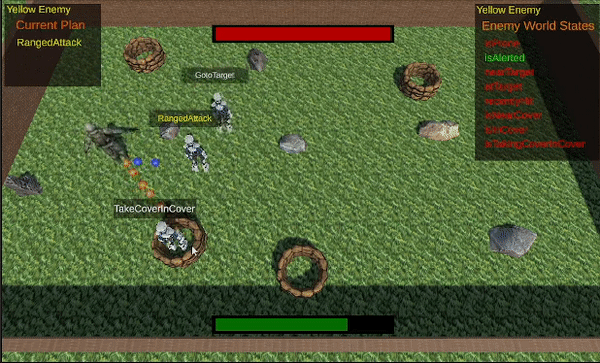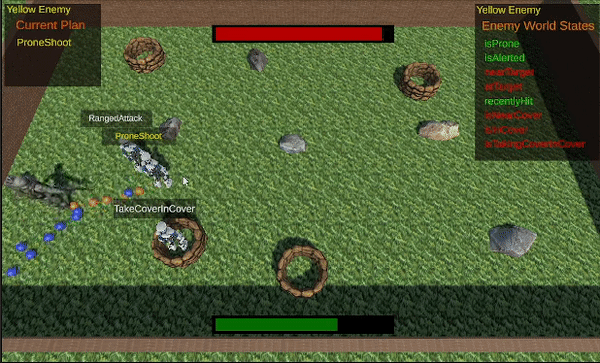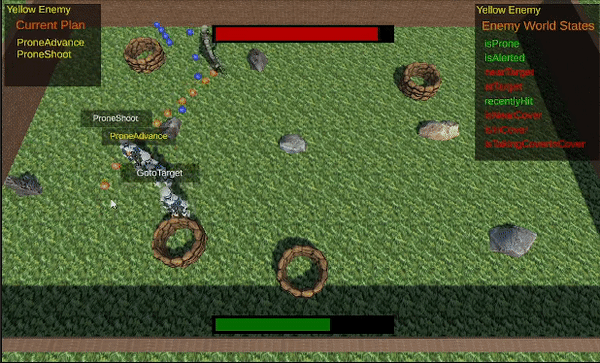
I also implemented a few prone actions (Prone shoot and Prone advance), a more defensive stance, simulating the AI actor dropping to the ground to avoid being hit, that the AI actor will prefer if being actively attacked by the player. The AI actor will take less damage when prone, but taking damage during a melee attack will not trigger prone.

The AI actor uses more defensive prone actions when attacked.
I also ran into some problems with the world state system, in particular concerning range checks. Sometimes, when a Ranged attack plan was made, the AI actor was in range to perform a Ranged attack, but not when the attack was to be performed, meaning the AI actor would not move to get in range (the plan told him it was already in range).
So I implemented a system where world states concerning ranges would be checked and changed constantly, not as an effect of an action.
Week 4: The Last Feature
The initial plan was to implement squad behaviours this week, but this had always been a cuttable stretch goal. I still wanted to implement one more type of behaviour and start polishing what I had, so squad behaviours were cut.
The last feature of the game was a set of actions of utilizing covers. I placed a few assets in my game scene that should represent a trench, a collection of sandbags, or something similar. The idea was that if the AI actor was attacked by the player when "close enough" to a place of cover, the AI actor should always prioritize moving into the cover, rather than going prone.
By this time I had gotten a hang of the system and could implement this rather quickly! The ranged attacks made from cover could also be designed to differ from other ranged attack. Furthermore, if the AI actor is attacked while in cover, it will stop shooting and duck down, to avoid getting hit.
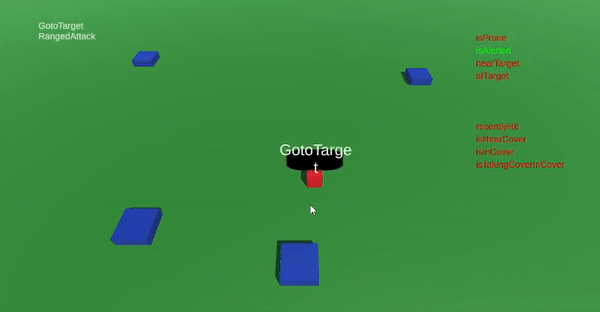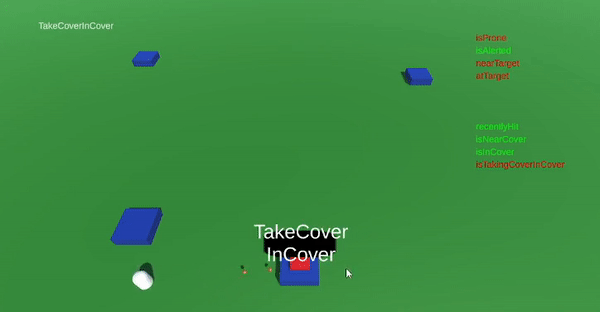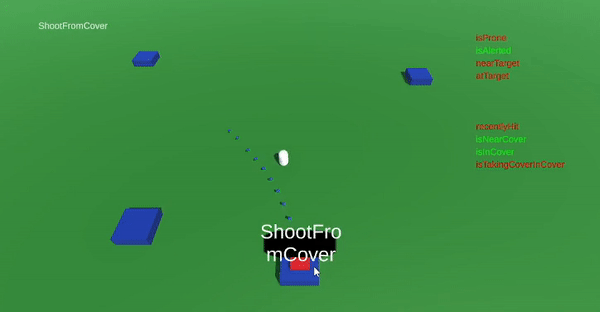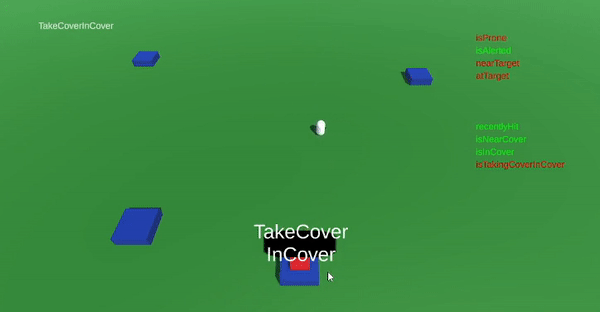
The AI actor can take cover, if close enough to a defensible position.
Week 5: Make It Presentable
Last week of the project. All my implemented features were working good, and I was quite happy that I had set a deadline for feature stop. Now I could focus on cleaning up the code, removing some unnecessary actions, and get rid of the placeholder graphics. Sadly, I did not have time to implement animation on my actors, but I am quite pleased how the AI system turned out!
The final result.
Further Improvements
The framework I created has a good foundation, but there is a couple of things that should be changed or expanded upon, that I would have liked to improve upon given time.
-
Sensory system. In most GOAP implementation, there is a system for the AI actor which determines what they can see, hear, feel, and in general to receive information about what they know about the world. In this project, I had to implement such sensory information manually from case to case, outside of a proper system.
-
World Node/Pathfinding system. For combat-oriented enemies, it would really improve the gameplay experience if there were designated locations or objects (nodes) in the world, that the AI actor could utilize. With such a system, you could have AI actors flanking, finding and waiting in an ambush spot, jump through windows, and similar. This would also make it easier to design enemies that will not just run straight at the player.
-
Refactor world state system. The world state system is quite clunky to work with right now. At the moment, they are stored in a HashSet containing KeyValuePair<string, bool>, and Getting/Setting items in the HashSet is a hassle. This runs together a bit with the Sensory system implementation that should be done.